Л. В. Щавелёв, С. Д. Коровкин, И. А. Левенец
Ивановский Государственный Энергетический Университет
Агрегация и интеллектуальный анализ информации Хранилищ Данных
(Новые информационные технологии: материалы науч.-практ. семинара / Моск. гос. ин-т электроники и математики. - М., 1998)
Управление любой сложной социально-экономической системой - от организации или предприятия до региона или государства - весьма затруднительно без обратной связи, которая заключается в отслеживании и анализе данных, отражающих состояние этой системы и ситуацию вокруг нее. Постоянная доступность актуальной информации дает возможность оценить текущее положение дел, а обзор изменения конкретных характеристик во времени позволяет обнаружить тенденции развития системы и сделать выводы о том, что ожидает ее в будущем. Таким образом, обладая всей полнотой сведений о состоянии системы и ее элементов в статике и динамике, управляющий персонал может принимать грамотные решения по применению мер регулирования. Такое управление основано на знании и потому более эффективно, чем принятие важных решений вслепую.
На современном этапе проблемы ведения баз данных (БД) оперативной информации на разных уровнях управления перестали быть непреодолимыми. Поэтому наиболее актуальной проблемой является не только и не столько проектирование и наполнение специализированных БД, сколько интегрированный взгляд на сложный объект управления в целом, комплексный анализ собранных о нем сведений и извлечение из огромного объема детализированных данных некоторой полезной информации - знаний о закономерностях его развития.
Поддержка принятия управленческих решений на основе накопленной информации может осуществляться в трех основных областях [10].
-
Область детализированных данных. Это сфера действия большинства транзакционных систем (OLTP), нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами.
-
Область агрегированных показателей. Комплексный взгляд на собранную в Хранилище Данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP) [5, 3]. Здесь можно или ориентироваться на специальные многомерные СУБД, или (что, как правило, предпочтительнее) оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД.
-
Область закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining) [2], главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или (с определенной вероятностью) прогнозируют развитие рассматриваемых процессов.
Некоторые авторы [10] выделяют в отдельную область анализ отклонений (например, в целях отслеживания колебаний биржевых курсов). В качестве примера может быть приведён статистический анализ рядов динамики [1]. Чаще, однако, этот тип анализа относят к области закономерностей.
Разработанный авторами программный комплекс ИнфоВизор является инструментальной оболочкой для создания информационно-аналитических систем (ИАС), покрывающих все перечисленные типы обработки данных. Основой представления информации о структуре используемых совместно с инструментарием ИнфоВизора реляционных БД являются метаданные. Благодаря их наличию практически любая непротиворечиво спроектированная БД может быть адаптирована к использованию в качестве содержательного наполнения ИАС на основе этого инструментария. Таким образом достигается инвариантность программного обеспечения по отношению к структуре представления исходной информации.
Поиск информации
Задача интеграции и согласования данных специализированных баз, являющихся информационными стержнями конкретных систем обработки данных (СОД) [3], в единое Хранилище Данных, равно как и задачи навигационного поиска в нем, корректировки и модификации детализированных данных, являются прерогативой корпоративных информационно-поисковых систем. Такую роль в комплексе ИнфоВизор играют системы ИнфоВизор-Реестр и ИнфоВизор-Загрузка, однако проблемы их разработки выходят за рамки данного доклада.
Многомерный анализ
Авторами разработан оригинальный механизм извлечения агрегированной многомерной информации любой степени обобщения из реляционных БД произвольной структуры. В дополнение к общепринятым в информационных системах навигационным (navigational), управляющим (operational) и реляционным (RDBMS) метаданным [8] ИнфоВизор вводит в Хранилища Данных аналитические метаданные, которые содержат набор информационных моделей ("виртуальных звезд"), позволяющих извлекать из него обобщенную численную информацию в многомерном базисе измерений.
За основу аналитических метаданных взято понятие многомерного гиперкуба. Осями гиперкуба (атрибутами информационной модели) могут быть любые способы консолидации данных [5], представляемые справочниками экземпляров некоторых объектов (множеством точек оси). Одной из осей гиперкуба может являться время, что позволяет анализировать динамические процессы. Совокупность выбранных экземпляров от каждой оси однозначно характеризует ячейку гиперкуба в пространстве объявленных атрибутов. Каждая ячейка гиперкуба может содержать численное значение - показатель, - смысл которого определяется координатами ячейки - набором экземпляров, по одному от каждого атрибута.
Получение значений показателей производится по результатам SQL-запросов к реляционной БД, которые автоматически генерируются ядром системы, исходя из диалогового запроса пользователя-аналитика к информационной модели. При этом результирующими значениями показателей информационной модели могут быть:
-
значения полей численного типа БД (предварительно агрегированные значения);
-
функции агрегирования SQL (avg, count, max, min, sum, а также другие функции агрегирования, поддерживаемые SQL-сервером [7]);
-
формулы (SQL-выражения, имеющие на выходе одно численное значение).
Атрибут - это один из признаков показателя, который может быть представлен в виде оси информационной модели. В литературе его еще часто называют измерением. Но в предлагаемой нами концепции понятие измерения более сложно: на этапе обработки ранее извлеченной информации и формирования отчетов измерения могут быть не только получены непосредственно из атрибутов, но и являться группировками нескольких независимых осей - атрибутов. Это делается для снижения общего количества измерений гиперкуба ради удобства конечного пользователя (довольно трудно манипулировать абстрактными пространствами с высокой мерностью).
Для обеспечения возможности рассматривать показатели с разными степенями агрегации реализация каждого атрибута, в общем случае, может быть выполнена с помощью нескольких конкретных справочников экземпляров - различных уровней обобщения атрибута. Так, атрибуту "Местоположение" можно поставить в соответствие несколько реализаций - уровень детализированного справочника СОАТО, уровень городов и районов, уровень субъектов Российской Федерации и так далее. Атрибут "Время" может иметь уровни обобщения с точностью до года, квартала, месяца и так далее.
Для некоторых осей методы получения значений определяемых ими слоев ячеек гиперкуба могут варьироваться в зависимости от выбора для рассмотрения конкретных экземпляров справочников уровней соответствующих атрибутов. Такие справочники (равно как и соответствующие им уровни) будем называть группируемыми. В соответствии с этим любая ось может быть разделена на группы однородности. Крайними являются случаи совпадения всего множества экземпляров справочника с одной группой и соответствия каждого экземпляра собственной единичной группе. Описание методов получения значений ячеек, принадлежащих слою гиперкуба, определенному группой однородности уровня атрибута, задается соответствующим этой группе отрезком однородности. Взаимные пересечения отрезков, определяющих группы однородности уровней атрибутов, определяют области однородности получения значений ячеек в рамках всего гиперкуба. Для всех ячеек одной области однородности значения могут быть извлечены с помощью одного SQL-запроса (поэтому любой диалоговый запрос пользователя к информационной модели, приводящий к формированию только одного SQL-запроса к БД, будем называть элементарным диалоговым запросом). Соответственно, если извлекаемое по заказу аналитика подмножество гиперкуба включает несколько областей однородности, то заполнение его значениями возможно по результатам выполнения самостоятельных SQL-запросов для каждой области в отдельности.
Помимо формального описания процесса построения SQL-запросов для получения значений показателей, характеристика каждой области однородности должна включать информацию о смысловых ограничениях содержимого своих ячеек. Дело в том, что, исходя из особенностей предметной области, значения каждой отдельной области однородности имеют практический смысл только тогда, когда они находятся в пространстве как минимум некоторого определенного для них набора измерений, удаление из запроса хотя бы одного из которых приводит к обессмысливанию всех значений области. Поэтому для каждой области однородности должен быть определен критический набор атрибутов, выбор которых для классификации показателей обязателен для расчета значений всей области. В результате формируется не только набор достаточных условий построения SQL-запросов, связывающих отрезки однородности уровней обобщения атрибутов с областями однородности информационной модели, но и набор необходимых условий, определяющих критический набор атрибутов, необходимых для получения значений каждой области.
Результаты серии SQL-запросов, сформированной по каждому конкретному оперативному заказу аналитика (диалоговому запросу), имеют совершенно идентичный формат (набор полей идентификаторов экземпляров справочников выбранных уровней обобщения выбранных атрибутов плюс целевое поле показателя), поэтому могут быть составлены в одну временную таблицу (например, оператором UNION), которая в совокупности со справочниками уровней обобщения атрибутов может рассматриваться как самостоятельная база данных, имеющая схему звезды (Star Scheme) [3, 5]. Тот факт, что центральная таблица этой БД является временной, то есть оперативно создается и заполняется по требованию аналитика в ответ на его нерегламентированный запрос, является основанием наименования описанного метода - "Концепция виртуальной звезды". Таким образом, предлагаемая концепция является целостным законченным оригинальным способом реализации гибких информационно-аналитических систем класса OLAP. Система ИнфоВизор-Аналитик основывается именно на этой концепции.
Физическое описание информационных моделей для агрегации информации производится в системных таблицах аналитических метаданных. Эти таблицы включаются в структуру исходной БД, после чего система ИнфоВизор-Аналитик позволяет пользователю строить и выполнять диалоговые запросы к содержащимся в них информационным моделям. В ходе построения запросов пользователь выбирает:
-
подмножество определенных в модели атрибутов, по которым он ожидает выполнения классификации значений;
-
один из возможных уровней обобщения для каждого выбранного атрибута;
-
подмножество экземпляров каждого выбранного уровня обобщения атрибута посредством установки соответствующего фильтра.
Фильтр может устанавливаться по прямому указанию набора элементов или по определению логического условия, которому выбранные элементы должны удовлетворять. Если реализация справочника поддерживает иерархию элементов, то установление фильтра по набору позволяет производить навигацию по его древовидному отображению.
Сформированный по результатам выполненного запроса информационный гиперкуб является самостоятельной структурой данных, подготовленной для проведения анализа. Он может быть сохранен в виде файла и использован повторно без восстановления подключения к исходной БД.
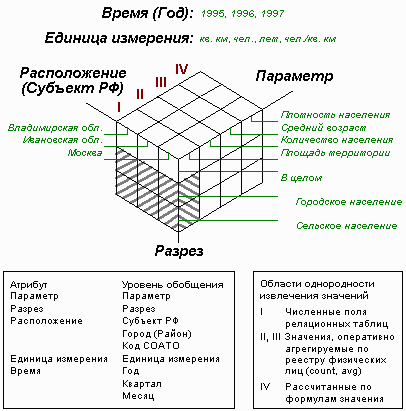
Рис. 1. Пример гиперкуба, полученного с помощью пятимерной виртуальной звезды. Серой штриховкой обозначены ячейки, показатели которых не имеют смысла. Предполагается, что исходное Хранилище Данных включает справочник административно-территориальных образований с информацией о площади территорий и реестр физических лиц с данными о месте жительства и дате рождения каждого жителя России.
Новизна предлагаемого подхода "виртуальной звезды" по сравнению с существующими механизмами, реализованными в продуктах OLAP, заключается в следующем.
-
Введение понятий группируемого справочника уровня обобщения атрибута и области однородности извлечения значений позволяет в рамках одной информационной модели обращаться к значениям трех типов: 1) предварительно агрегированным в полях численного типа, 2) полученным в результате оперативной агрегации в процессе выполнения запроса и 3) являющимся результатами расчета заданных формул. Таким образом, построенный пользователем диалоговый запрос может возвратить значения, принадлежащие ко всем этим типам, в рамках одного гиперкуба. При этом в процессе построения информационной модели можно достичь допустимого компромисса между быстротой доступа к заранее агрегированным значениям и актуальностью значений, агрегируемых оперативно. Даже для разных экземпляров одного справочника одной оси могут быть заданы различные методы доступа, исходя, например, из частоты обращения к соответствующим значениям.
-
Реализация гибкого механизма группировки атрибутов - элементарных измерений - в процессе рассмотрения сформированного гиперкуба в укрупненные измерения позволяет существенно понизить его мерность и облегчить восприятие конечным пользователем содержащейся в нем информации.
Разработанная авторами система ИнфоВизор-Аналитик реализует клиентскую часть описанной OLAP-системы и позволяет производить оперативный многомерный анализ численных данных реляционных БД произвольной структуры. С другой стороны, система ИнфоВизор-Администратор предназначена для интерактивного редактирования информационных моделей аналитических метаданных этих БД.
Интеллектуальная обработка данных
Ядро OLAP-системы обеспечивает извлечение агрегированных показателей в многомерном базисе измерений. В таком виде численная информация удобна для просмотра и построения отчетов, но в том, что касается собственно аналитической обработки, продукты OLAP сами по себе могут выполнять только простейшие действия. Для сложных способов анализа информации инструментарий OLAP может рассматриваться исключительно как средство подготовки исходного материала.
Методы извлечения знаний из БД, объединяемые под маркой Data Mining (или Knowledge Discovery in Databases), являются современным воплощением основных идей Искусственного Интеллекта [9]. Целью интеллектуальной обработки является поиск скрытых закономерностей в данных, причем могут выполняться действия для обнаружения закономерностей нескольких типов: классификация, кластеризация, выявление ассоциаций, выявление последовательностей, прогнозирование, а также некоторые другие, менее распространенные операции [9, 2]. Вообще говоря, процесс интеллектуальной обработки может быть двух видов [10]:
-
подтверждающий (confirmatory) анализ (задача - подтвердить или опровергнуть выдвинутые гипотезы);
-
исследовательский (exploratory) анализ (изначально о виде закономерностей ничего не известно, и выполняется свободный поиск всех аномалий в заданной области данных).
Свободный поиск должен обеспечивать возможность динамических настроек ("Какая часть имеющихся данных исследуется?", "Какие значения свойств аномалий в данных следует считать пороговыми?" и тому подобное). Кроме того, этот поиск, как правило, проводится в несколько итераций (после получения очередных результатов может возникнуть необходимость включить в область исследования новые атрибуты, расширить пространство поиска и так далее).
Большинство существующих сегодня инструментов интеллектуального анализа ориентированы на непосредственную обработку реляционных данных (иногда даже требуется собрать все примеры обучающего множества в одну большую плоскую таблицу). Только недавно на стыке областей OLAP и Data Mining начали выделять гибридную область многомерного интеллектуального анализа [11]. Именно такой вариант обработки реализуется в системе ИнфоВизор-Аналитик. Ядро системы реализовано так, что к полученному с помощью информационной модели гиперкубу показателей через открытый интерфейс информационного обмена могут динамически подключаться внешние модули интеллектуального анализа. Например, реализован модуль подтверждающего анализа для прогнозирования динамических процессов на основе методов математической статистики. Из построенного гиперкуба выделяются вектора показателей вдоль измерения времени, среди них выделяется ряд процессов, предположительно связанных друг с другом, и проверяется наличие корреляции между этими рядами динамики [1]. После этого в случае обнаружения существенной корреляции может быть построена формула множественной регрессии, по которой один из рассматриваемых процессов, выбранный в качестве целевого, может быть исследован по сценарию "что - если". Аналогичный подключаемый модуль может быть построен на основе нейронных сетей [4] - в нем после определения матрицы корреляций и разделения вовлеченных в нее процессов на целевые и факторные вместо регрессионной формулы может быть построена и обучена нейронная сеть (многослойный персептрон). Во многих случаях такая сеть может аппроксимировать важные, но неформализуемые иными способами закономерности.
Что касается исследовательского анализа (свободного поиска), то для собранных в гиперкубе агрегированных данных предлагается использовать разрабатываемый сейчас модуль индукции правил методом отделения и захвата [6]. В отличие от индукции деревьев решений, а также от методов классификации на основе нейронных сетей или методов ближайшего соседа, индукция правил позволяет получать на выходе алгоритма списки неиерархических перекрывающихся легко интерпретируемых символьных правил. При этом в случае, если в ячейках гиперкуба расположены аддитивные показатели (например, значения функций агрегирования count или sum), по всем измерениям могут быть подсчитаны результирующие суммы [7]. Тогда поиск может производиться не только в максимально полном гиперкубе, но и в любой его проекции, полученной для каждого подмножества составляющих его измерений. Таким образом может быть исключена опасность получения неадекватных результатов, риск выдачи которых присутствует при одновременном учете слишком большого числа независимых характеристик в процессе поиска правил в плоской таблице данных [11]. Идея самого метода отделения и захвата [6] заключается в последовательной индукции логических правил, покрывающих часть обучающего множества, с удалением на каждом шаге из обучающего множества покрытых примеров. Результатом индукции становится список правил, генерируемых до тех пор, пока обучающее множество не станет пустым. При этом правила формируются и выбираются согласно определенным эвристикам, основные из которых нацелены на максимизацию достоверности правила по свидетельствам известных примеров при одновременной минимизации сложности правила. Динамическая настройка такого метода при использовании его для извлечения знаний из данных гиперкуба должна заключаться, во-первых, в определении относительной значимости эвристик (с возможностью выбора классического набора значений по умолчанию), а во-вторых, в определении пороговых признаков аномалии в данных, при достижении которых сгенерированное правило может считаться значимым результатом свободного поиска.
В настоящий момент система ИнфоВизор-Аналитик реализована в технологиях клиент-сервер и Intranet. Система предназначена для изучения содержимого Хранилищ Данных, многомерного анализа агрегированной информации, генерации табличных, графических и топографических отчетов, а также для подготовки исходных данных для динамически подключаемых через открытый интерфейс информационного ядра внешних модулей интеллектуального анализа. Инструментальный подход позволяет проектировать конкретные информационно-аналитические системы посредством создания слоя аналитических метаданных, содержащего набор информационных моделей - "виртуальных звезд" - для описываемого Хранилища Данных. Система может применяться для анализа экономического положения, обработки данных социологических опросов, проведения исследований при подготовке и проведении выборов, изучения демографических, социальных и многих других процессов.
Список литературы
- Я. Я.-Ф. Вайну. Корреляция рядов динамики. - М.: Статистика, 1977. - 119 c.
- Н. Кречетов, П. Иванов. Продукты для интеллектуального анализа данных // ComputerWeek-Москва. - 1997. - N 14-15. - С. 32-39.
- А. А. Сахаров. Концепции построения и реализации информационных систем, ориентированных на анализ данных // СУБД. - 1996.- N 4. - С. 55-70.
- Ф. Уоссермен. Нейрокомпьютерная техника: Теория и практика. - М.: Мир, 1992. - 240 с.
- E. F. Codd, S. B. Codd, C. T. Salley. Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate. - E. F. Codd & Associates, 1993.
- J. Fuernkranz. Separate-and-Conquer Rule Learning. - Vienna: Austrian Research Institute for Artificial Intelligence, Technical Report OEFAI-TR-96-25, 1996.
- J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow, H. Pirahesh. Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals // Data Mining and Knowledge Discovery. - 1997. - N 1. - P. 29-53.
- J. Hurwitz. The Evolution of Metadata // DBMS. - 1997. - Vol. 10. - N 8. - P. 12-15.
- H. P. Newquist. Data Mining: The AI Metamorphosis // Database Programming & Design. - 1996. - N 9 (Data Mining Special Edition Supplement). - P. S12-S14.
- K. Parsaye. New Realms of Analysis: Surveying Decision Support // Database Programming & Design. - 1996. - N 4. - P. 26-33.
- K. Parsaye. OLAP & Data Mining: Bridging the Gap // Database Programming & Design. - 1997. - N 2. - P. 30-37.





